Since the release of ChatGPT in November 2022, there has been an explosion of interest in large language models (LLMs), with numerous open-source and proprietary models entering the market. As competition intensifies, LLM providers are increasingly focusing on efficiency as a key differentiator to attract users and stay ahead of the curve.
In the race to develop the most advanced and capable LLMs, much of the media attention has been centered on the quest for Artificial General Intelligence (AGI). However, as the market matures, cost and performance efficiency are emerging as critical factors that will determine the success of LLM providers. This shift in focus is driving innovation in pre-training and inference techniques, as providers strive to deliver models that are not only more accurate but also faster and more cost-effective than their competitors.
Analysis
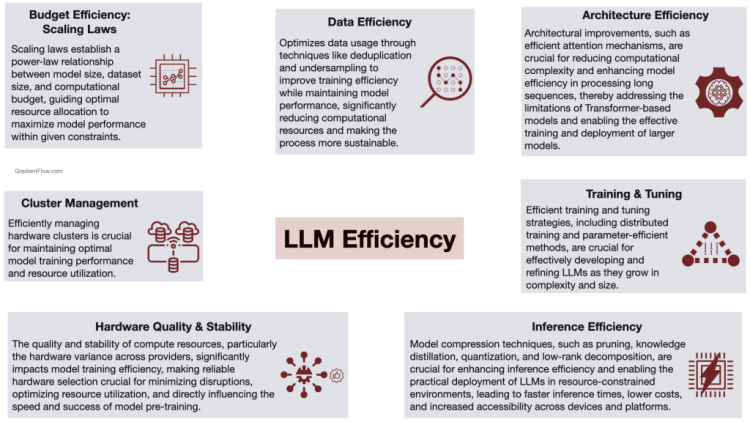
- Data Efficiency as a Competitive Lever: Mistral AI’s success in developing smaller, more efficient models is largely attributed to their prowess in filtering out repetitive or nonsensical information from training data. Investing in data tools and expertise can yield significant returns in terms of model performance and cost savings. This highlights a critical need for industry-wide investment in sophisticated data tools tailored for diverse data types, similar to the pivotal role Visual Layer plays in computer vision.
- Architectural Innovations Leading the Charge: The remarkable strides made by Google’s Gemini 1.5 and Mistral’s Mixtral 8x7B, through sparse architectures and Mixture of Experts engines (MoE), exemplify how architectural innovation can drive efficiency. These models not only challenge the status quo with reduced compute demands but also herald a new era of cost-effective, high-performance LLMs.
- Hardware Quality and Strategic Partnerships for Efficiency: The efficiency of model training is heavily influenced by the quality and stability of compute resources, particularly the inconsistency in hardware performance across various providers. Key factors affecting training efficiency include the overall cluster quality and the performance of accelerators such as GPUs or TPUs. Companies should prioritize hardware assessment and strategic partnerships, leveraging tools like Ray for efficient cluster management and distributed training, ensuring stability and scalability in their AI projects.
- Emphasizing Cluster Management and Orchestration: Efficient management of computational resources and the strategic use of orchestration tools are indispensable for scaling AI operations without compromising performance. These tools not only optimize resource allocation but also enable flexibility, seamless scalability, and fault tolerance, which are key for managing complex AI workflows.
Efficiency in pre-training is not just an operational advantage – it’s a catalyst for innovation and agility in AI development
- Inference Efficiency: With advancements in model compression and pruning techniques, inference efficiency has become a focal point for deploying LLMs in resource-constrained environments. Adopting strategies like pruning and quantization, businesses can dramatically reduce operational expenses, extending the reach and accessibility of LLM technologies.
- The Strategic Advantage of Efficient Pre-training: The move towards more efficient pre-training methods is not just about cost savings; it’s about agility and innovation. Faster, less resource-intensive training cycles allow for more experimentation and rapid deployment of improved models, offering a strategic edge in a competitive market.
- Survival of the Efficient (and the Deep-pocketed): This shift towards efficiency also aligns better with the evolving investment landscape, where the focus is increasingly on developing scalable, profitable AI solutions that address specific business needs rather than chasing the elusive goal of AGI. This means startups building foundation models need to be extremely capital and resource efficient, or be attached to a profitable company (e.g. Google, Meta). To achieve this, the model provider’s executive team must be fully committed and focused on the task at hand, which may be challenging if they are involved in numerous other side hustles.
- Interchangeability and Flexibility in Model Selection: Don’t be swayed by hype. While some companies dominate tech headlines with new models, remember: the competitive landscape is constantly shifting. Competitors and open source models often catch up in performance within months. This underscores the importance of building applications and systems that offer the flexibility to integrate models from various providers. This ensures access to the best-performing models at any given time, freeing your team from vendor lock-in.
In the era of Generative AI, being better, faster, and cheaper is essential for success. To achieve this, focus on efficiency in your AI applications, even if you’re not training your own LLMs. Prioritize data quality, optimal resource utilization, streamlined processes, and innovative architectures to deliver cutting-edge solutions that drive meaningful results. By embracing an efficiency-first mindset, your AI team can stay ahead of the curve and create impactful applications that leverage the power of foundation models.
If you enjoyed this post please support our work by encouraging your friends and colleagues to subscribe to our newsletter:
The post The Efficient Frontier of LLMs: Better, Faster, Cheaper appeared first on Gradient Flow.



















